Русский язык по способу образования форм слова есть флективный язык, то есть в языке существуют флексии - часть слова (окончание), выражающая грамматическое значение при словоизменении (склонении, спряжении). Также он является синтетическим языком - в слове объединено и лексическое и грамматическое значение.
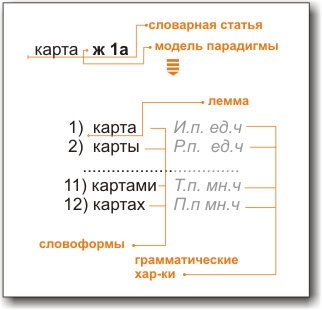
Совокупность форм слова называется лексемой (общая система лексических значений). Система словоформ, относящихся к одной лексеме, называется ее парадигмой. (Наиболее сложную парадигму в русском и других индоевропейских языках имеют глаголы. У неизменяемых слов лексема и словоформа совпадают). В словарях каждая лексема представлена одной из словоформ, которую называют исходной(нормальной) формой - или леммой, а сам процесс сведения словоформы к лемме - называют лемматизацией.
В русском языке нормальными формами являются: для существительных - именительный падеж единственного числа, для прилагательных - именительный падеж единственного числа мужского рода, для глаголов, причастий и деепричастий - глагол в инфинитиве.
Из чего состоят слова?
Морфология имеет дело со словоформами, которые членятся на минимальные единицы морфы.
Традиционное членение грамматики на морфологию (грамматику слова) и синтаксис (грамматику словосочетания и предложения) важнее всего для языков с четкой структурной противопоставленностью слова и морфемы (в языках синтетического типа). По мере нарастания аналитизма (языки аналитического строя) - это членение теряет свою ценность. В описаниях языков с бедной морфологией (английский, китайский, индонезийский, тибето-бирманские языки и др.) морфология как раздел грамматики отходит на задний план для аморфных («корневых») языков (др.-кит., тайские, вьетнамский, йоруба и др.) значимость морфологии практически сводится к нулю.
Морфология английского языка была компактно описана и формализована McIllroy еще в 1978. Проблема полного описания морфологии русского языка была удачно решена Зализняком А.А. в конце 70-х годов. Над описанием морфологии около 100 000 слов, составляющих ядро общеупотребительной лексики, он трудился в течение 20 лет. Результатом стал "Грамматический словарь русского языка", который переиздавался на данный момент уже 4 раза.

Для чего нужна морфология?
При автоматизированной обработке текстов (англ. Natural language processing, NLP) как правило все формы слов приводятся к лемме(нормальной форме) для удобства хранения и поиска. Если поисковик разработан с учетом морфологии - это означает, что поиск будет идти по всем формам слов. Например, если задан запрос идти, то поиск будет производиться по словам идти, идет, шел, шла...
Более широкое описание задач обработки текста смотрите в
"Статье про корпуса. Парсер".
Для работы с морфологией естественно необходимо где-то словарь хранить. Существует несколько подходов в данной области. Разберем их чуть подробнее...
Расцвет рынка программного обеспечения для русских словарей был в середине 90-х годов. Основные модели, которые успешно действуют до сих пор, были разработаны для слабых, по нынешним меркам, процессоров с небольшим количеством памяти. Бывало и так, что кодирование слов не всегда было однозначным (транзитивным). Словарь общей лексики на 100 тысяч лемм умещали в 300-400кб при помощи унификации флексий. Проще говоря, из всех слов выделяли постоянную графическую часть, цепочки изменяющихся префиксов и суффиксов хранили отдельно. Информация о грамматических характеристиках дополнительно требовала дополнительно 100-200кб, в зависимости от принятой классификации частей речи.
Cтэмменг слов - это всего лишь алгоритм выделения корня в слове. По сути дела не является методом хранения, однако, обязательно нужно упомянуть о нём, т.к. стеммеры - это важная часть NLP и используются почти в каждом проекте.
Спеллеры - это наиболее распространенные методики словари позволяющие осуществлять проверку орфографии и анализа слов. Спеллеры оказались довольно универсальным средством для многих языков и получили большое распространение. В этом подходе используется система хранения "префиксы+основа + список возможных окончаний", а так же механизм выделения основы с дальнейшим поиском флексий.
Метод был освоен математиками еще в 60-х 70-х годах 20-го века. Это один из быстрых способов доступа к данным словаря использующий вспомогательную функцию, которую называют хэшем (от англ. hash). Преимущество данного метода в том, что сложность функции поиска слова в хэш-таблице составляет O(1) т.е. является константой. Подробнее о методе можно прочитать в "Индексирование русских текстов с использованием словаря, представленного на основе разреженной хэш- таблицы" Способ представления словаря: хэш-таблица. Судя по всему - хэширование закрытым ключом с ранжированием флексий.
Еще один быстрый алгоритм доступа к данным словаря - это использование древовидной структуры. В английском варианте B-tree. Данный метод позволяет за конечное количество итераций найти слово в словаре. И по сравнению с Хэш-таблицей может быть компактнее при хранении больших объемов данных. Ознакомьтесь с сайтом Андрея Коваленко Здесь, способ представления словаря: дерево (B*-tree). Как это иногда называют "конечный автомат".Скорости разбора и анализа не уступают хэш-таблице. Словарь занимает в памяти столько же сколько и на диске. Принцип поиска аналогичен работе жесткого диска. Не использует ни одного malloc/new (т.е. динамического выделения памяти).
Н-граммы, используются в данном проекте mcr.dll - это методика позволяющая хранить сразу целые цепочки корней и аффиксов длиной N, что дает некоторые преимущества и некоторые особенности при использовании орфокоррекции или в генетических алгоритмах генерации псевдослов.
У всех методов свои преимущества. Какой механизм ведения словаря является самым быстрым? Занимает меньше памяти и хранит больше слов? Задаваясь такими вопросами, было предложено запустить на одном стенде тесты (benchmark tests) и посмотреть основные характеристики работы в условиях однопоточного 32-битного приложения, а так же предоставить все исходные тексты, чтобы проверить это на различных архитектурах. Смотрите статью Сравнение API словарей .
Открыв первую страницу словаря русского языка А.А Зализняка 2-й редакции, вы сразу попадете на описание (и дополнительные правила, ограничения) частей речи в словаре. Существует некоторое количество способ классификации слов, при этом, школьная классификация частей речи в русском языке - является обобщением нескольких классификаций, и вовсе не является эталонной. По сути дела, вопрос о частях речи в русском языке можно считать открытым, а систему которая предложена в словаре Зализняка Вам (возможно) придется расширить. (см. статью о морфологии)
Идея построения базы словаря mcr была основана на методе Вилбура-Ховайко. При первичном рассмотрении разделов лингвистики посвященных словообразованию, выяснилось - что схем деления слов на части - несколько и все они "не совсем" однозначны. Были изучены словари Кузнецовой и Розенталя которые дают необходимые достаточно формализованные системы правил, построения, разбиения слов (то как и из чего состоят слова).Были предприняты попытки использовать, в качестве минимальной единицы слова - слог, что приводило к серьезному перебору; была рассмотрена система словообразования "корень+аффиксы", что тоже окзалось весьма затруднительным. В итоге вопрос об однозначном разбиении слова был какое-то время нерешенным.
В связи с этим, в качестве морфемы была выбрана математическая величина н-грамма, а именно 3-грамма. Во-первых, это позволило уместить 3-байта информации в 2-х. Во-вторых, получить возможность работы с разными алфавитами и вести словарь для любого* языка по один и тем же функционалам и организовать более быструю функцию орфокоррекции.
Что же делать если слово отсутствует в словаре? Как его индексировать для поиска?
Словари достаточно ограничены в объеме, да и описать все слова нашего языка задача весьма неопределенная; язык как и наш мир постоянно развивается. Поэтому словари обычно снабжают функцией "угадывания" словоизменения для "новых" слов которые отсутствуют в словаре. Смотрите функцию int orfo в mcr.dll для построения гипотез о словоизменении "незнакомых" слов. В данном случае словарь mcr использует генетические алгоритмы сращивания н-грамм на основе данных находящихся в словаре. Используйте все найденные вами признаки для незнакомых слов - это уточнит выбор модели парадигмы.